오늘은 머신러닝과 딥러닝에 대해 정리해 보겠습니다. 인공지능 기술 중 가장 잘 알려진 챗GPT와 같은 생성형 AI를 포함하여 이러한 인공지능 기술의 핵심 중의 핵심, 기본 중의 기본이 되는 머신러닝과 딥러닝에 대해 이 들의 관계를 어떻게 되는 건지, 이들의 차이점은 무엇인지 정리해 보겠습니다.
머신러닝과 딥러닝 차이
아침에 일어나 스마트폰으로 날씨를 확인하고, 출근길에 스트리밍 서비스가 추천해 주는 노래를 듣습니다. 점심 메뉴를 고민할 때는 맛집 추천 앱을 켜보고, 퇴근 후엔 넷플릭스 같은 OTT 서비스가 내 취향에 딱 맞는 영화를 골라주죠.
이제 우리에겐 너무 당연하게 느껴지는 이런 세상. 이런 것들의 기반 기술이 인공지능(AI) 기술이라는 사실을 한번쯤은 들어 보셨을 거예요. 그런데, 이러한 인공지능 기술의 핵심에 머신러닝과 딥러닝 기술이 있다는 것은 나름 여기저기서 들어봤지만, 이들은 어떤 관계를 갖는지, 또 무슨 차이가 있길래 명칭마저 구분하는 것인지 이제 차례대로 설펴 볼게요.
머신러닝(Machine Learning)
한국어로 ‘기계학습’이죠. 말 그대로 기계가 스스로 학습하는 기술입니다. 여기에서 ‘학습’이란 말은 인간이 하나하나 규칙을 정해주지 않아도 컴퓨터가 입력되는 데이터를 통해 스스로 패턴을 인식하고 예측이나 결정을 할 수 있게 되는 것을 의미합니다.
예를 들어 스팸 메일 필터를 만든다고 생각해 볼게요. 인공지능 기술이 아닌 이전 방식이라면 개발자가 <‘광고’, ‘홍보’, ‘무료’ 등과 같은 단어가 포함되면 스팸으로 분류한다>라는 식으로 수많은 규칙을 직접 만들어야 했어요. 그러나 머신러닝 기술을 적용한다면 다릅니다. 정상 메일과 스팸 메일 샘플(데이터)을 잔뜩 보여주면, 컴퓨터가 알아서 어떤 패턴을 가진 메일이 스팸인지 학습하게 됩니다. 이렇게 학습한 컴퓨터는 나중에 새로운 유형의 스팸 메일에 대해서도 비교적 잘 대처할 수 있게 됩니다.
이러한 머신러닝은 학습 데이터의 형태나 방식에 따라 크게 3가지로 나뉩니다.
- 지도 학습 (Supervised Learning): ‘정답’이 있는 데이터로 학습합니다. 위 스팸 메일 예시처럼 ‘이 메일은 스팸’, ‘저 매일은 정상’이라고 표시된 데이터를 보고 학습합니다. 날씨 예측, 주가 예측, 이미지 분류 등에 사용됩니다.
- 비지도 학습 ( Unsupervised Learning): ‘정답’ 없이 데이터 그 자체의 숨겨진 구조나 패턴을 파악하는 방식. 비슷한 특성을 갖는 고객 그룹(Clustering)을 찾아내거나, 데이터의 이상 징후를 탐지하는데 활용됩니다.
- 강화 학습 (Reinforcement Learning): 보상을 통해 학습하는 방식입니다. 마치 강아지에게 ‘앉아’ 훈련을 시킬 때 잘 따라 하면 간식을 주어 칭찬하는 것처럼, 특정 행동을 했을 때 보상(Reward)을 주거나 벌점(Penalty)을 부여함으로써 최적의 행동 방식을 학습하도록 합니다. 자율 주행이나 게임 AI에 적용됩니다.
인터넷 쇼핑몰에서 물건을 구경하다 보면 “이런 상품은 어떠세요?”하고 비슷한 상품을 추천해 주는 기능, 유튜브나 넷플릭스에서 내가 좋아할 만한 영상을 추천해 주는 것도 대부분 머신러닝 기술이 적용된 결과입니다.
딥러닝(Deep Learning)
그러면, 딥러닝은 뭘까요? 딥러닝은 앞에서 설명한 머신러닝의 한 분야예요. 머신러닝이 보다 큰 범위라면 딥러닝은 머신러닝 중 아주 특별한 기술에 해당하는 거죠.
좀 전문적으로 말하자면, 딥러닝의 핵심은 바로 ‘인공신경망(Artifical Neural Network, ANN) 기술이에요. 이 인공신경망의 층(Layer)을 여러 개 깊게(Deep) 쌓아서 만들기 때문에 ‘딥러닝’이라는 이름이 붙었습니다.
인공신경망은 이름에서 알 수 있듯이 인간의 뇌 속에 있는 신경세포(뉴런)들이 서로 연결되어 정보를 처리하는 방식과 유사하게 만들어져요. 물론, 실제 뇌 구조와 똑같이 작동하는 것은 아니지만, 기본적인 아이디어를 참고한 거죠.
딥러닝 역시 머신러닝처럼 3가지로 구분할 수 있는데요,
- 입력층(Input Layer): 데이터를 입력하는 곳이죠. 예를 들면, 강아지 사진을 인식한다면, 사진의 각 픽셀 정보가 입력되는 부분입니다.
- 은닉층(Hidden Layer): 입력층과 출력층 사이에 있는 눈에 보이지 않는 층입니다. 눈에 보이지 않는다는 것은 은닉층을 프로그래밍 코드로 구성할 때 입/출력층만큼 구체화하지 않다는 뜻일 뿐 은닉층이 마치 숨어있는 어떤 것이라는 의미는 아니에요. 딥러닝은 이 은닉층을 여러 개 쌓아서 복잡한 문제를 해결합니다. 각 층은 입력된 데이터로부터 점점 더 고차원적이고 추상적인 특징들을 추출해 냅니다. 예를 들어 이미지의 첫 번째 은닉층에서는 선이나 모서리 같은 단순한 특징을 인식하고, 다음 층에서는 눈이나 코 같은 좀 더 복잡한 형태를, 그다음 층에서는 얼굴 전체의 윤곽을 인식하는 방식으로 점점 발전해 가는 방식입니다.
- 출력층 (Output Layer): 결과 출력부이고요, 강아지 사진을 판별하는 예를 들어보면, ‘이 사진은 강아지일 확률이 90%, 고양이일 확률이 10%’라는 식의 결과를 도출하는 부분이죠.
이러한 딥러닝이 자주 언론이나 인터넷에 노출된 이유는 가장 큰 부분은 자연어 처리 기술의 급격한 발전으로 대화가 가능한 생성형 AI 서비스, 즉 챗GPT의 등장과 딥페이크 문제가 사회적 이슈로 되었기 때문이 아닐까 싶습니다.
그래서, 머신러닝과 딥러닝의 차이는?
그러면, 앞에서 이미 딥러닝은 머신러닝의 한 종류라고 했는데, 그러면 왜 이들 머신러닝과 딥러닝을 굳이 구분해서 이야기하는 걸까?라는 궁금증이 생길 거예요. 가뜩이나 인공지능 기술도 잘 모르겠는데, 딥러닝을 이름부터가 뭔가 더 알고 싶지 않은 듯한 느낌적 느낌이죠.
일단, 복잡한 것은 싫으니 아래와 같이 표로 간단하게 정리해 보죠. (머신러닝과 딥러닝 비교)
| 구분 | 머신러닝 (Machine Learning) | 딥러닝 (Deep Learning) |
| 핵심 아이디어 | 데이터로부터 패턴 학습 | 깊은 인공신경망을 이용한 패턴 학습 |
| 특징 추출 | 주로 사람이 직접 수행 (Feature Engineering) | 모델이 스스로 학습하며 자동 추출 |
| 데이터 양 | 상대적으로 적은 양으로도 가능 | 대량의 데이터 필요 |
| 데이터 종류 | 정형 데이터에 강점 | 비정형 데이터(이미지, 음성, 텍스트 등) 처리에 매우 강력 |
| 하드웨어 | 일반 CPU로도 가능 | GPU 등 고성능 하드웨어 거의 필수 |
| 주요 알고리즘 | 결정 트리, SVM, 로지스틱 회귀 등 다양 | MLP, CNN, RNN 등 인공신경망 기반 |
| 해석 가능성 | 상대적으로 높은 편 | 낮은 편 (블랙박스) |
이 둘의 차이점에 대해 잘 이해가 되나요? 보면 알 것도 같고, 뭔가 이게 무슨 차이지 싶기도 하죠?
파이썬 코드로 보는 머신러닝과 딥러닝의 차이점
아무리 떠들어도 한번 직접 구현해 체험해 보는 것보다 더 잘 이해하는 방법은 없죠. 머신러닝 방법과 딥러닝 방식에 대해 직접 파이썬으로 구현해 보죠.
머신러닝과 딥러닝이 어떤 차이를 갖는지 보여주는 예시이므로, 문제를 아주 단순화해서 적용해 봐야겠죠?
우선, 집 크기에 따라 집 값이 예측하는 문제를 예시로 해 볼게요. 실제 현실에서는 여러 가지 조건(지역, 종류, 교육 등)이 붙어야 하지만, 예시이므로 집 크기만 변수로 적용해 볼게요.
집 크기에 따른 가격 데이터는 다음과 같이 간단하게 구성해 볼게요.
# 데이터 생성 (집 크기와 집값)
np.random.seed(42)
X = np.random.rand(100, 1) * 100 # 집 크기 (0~100 평)
y = 3 * X + 10 + np.random.randn(100, 1) * 10 # 집값 (선형 관계 + 약간의 노이즈)집 크기에 따라 가격 변화 데이터이므로, 가끔은 집 크기가 크더라도 낮은 값도 생성해야 하므로 노이즈를 적용해 봤어요. 좀 다양하게 가격 구성이 되도록 말이죠.
그럼 이제 이런 데이터를 머신러닝으로 학습하는 경우의 예시 코드를 볼게요.
from sklearn.linear_model import LinearRegression
lr_model = LinearRegression() # 선형 회귀
lr_model.fit(X, y)
y_pred_lr = lr_model.predict(X)scikit-learn은 파이썬에서 머신러닝을 구현할 수 있도록 하는 라이브러리예요. 아마, 현재까지 파이썬 3.12 이하 버전에서 적용될 거예요. 파이썬 3.13 버전 이상에서는 설치가 안된다는 걸 참고하세요. 최신 버전 파이썬 사용자는 이럴 때 아나콘다 가상환경을 적용해 보면 좋겠죠?
라이브러리를 설치했으면 위 코드처럼 LinearRegression 클래스는 임포트 합니다. 데이터 조건에서 선형적 관계를 이루며, X는 Y라는 질문과 정답의 형태이므로, 지도학습의 대표적인 모델은 선형회귀(Linear Regression) 모델을 적용했어요. (이번 글에서 이러한 모델에 대한 구분은 언급하는 것은 내용이 너무 많으므로 생략합니다.)
자, 다음은 같은 데이터를 적용해서 딥러닝 학습 모델을 만들어 볼게요.
먼저, tensorflow 라이브러리를 설치해 줘야 해요. 위 머신러닝처럼 tensorflow도 딥러닝을 구현하는 데에 필수적인 라이브러리예요. 다음과 같이 Sequential과 Dense 클래스를 임포트 합니다.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense앞의 선형회귀 클래스처럼 여기서도 Sequential 클래스와 Dense 클래스에 대한 설명은 생략합니다. 다만, 아래 코드처럼 딥러닝의 신경망을 구성하는 데에 있어서 ‘Sequential이 앞에서 언급된 입력층, 은닉층, 출력층 Layer를 총칭한다면, Dense는 각 Layer를 연결하는 망’ 정도로 생각하면 됩니다. 이런 의미로 다음 코드를 보시죠.
dl_model = Sequential([
Dense(units=10, activation='relu', input_shape=(1,)),
Dense(units=1)
])위 코드는 딥러닝 신경망을 두 개의 층으로 구성한 거예요. 그런데, 이렇게만 말하면 좀 혼란스러워요. 왜냐, 앞에서 딥러닝은 입력층, 은닉층, 출력층으로 구분된다고 했는데, 실제 코드에서는 두 개층으로 구성되는 거야?라고 할 수 있죠.
여기서, 위 코드를 자세히 보면 Sequential이 두 개의 층으로 구성된 것으로 보이지만, 윗부분 Dense 내부 요소를 보면 input_shap가 보입니다. 이 부분이 바로 입력층이 되죠. 즉, 입력층에서 1차원의 입력을 받아 은닉층의 10개의 뉴런에 전달하는 거죠. 그 다름 하나의 출력층으로 전달되는 거예요.
그럼 이제 전체 코드를 다음과 같이 구성하고, 실행해 볼게요.
import numpy as np
from sklearn.linear_model import LinearRegression
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
# 데이터 생성 (집 크기와 집값)
np.random.seed(42)
X = np.random.rand(100, 1) * 100 # 집 크기 (0~100 평)
y = 3 * X + 10 + np.random.randn(100, 1) * 10 # 집값 (선형 관계 + 약간의 노이즈)
# 머신러닝: 선형 회귀
lr_model = LinearRegression()
lr_model.fit(X, y)
y_pred_lr = lr_model.predict(X)
# 딥러닝: 신경망
dl_model = Sequential([
Dense(units=10, activation='relu', input_shape=(1,)),
Dense(units=1)
])
dl_model.compile(optimizer='adam', loss='mse')
dl_model.fit(X, y, epochs=100, verbose=0)
y_pred_dl = dl_model.predict(X, verbose=0)
# 결과 시각화
plt.scatter(X, y, label='데이터')
plt.plot(X, y_pred_lr, 'r-', label='선형 회귀 (머신러닝)')
plt.plot(X, y_pred_dl, 'b--', label='신경망 (딥러닝)')
plt.xlabel('집 크기 (평)')
plt.ylabel('집값 (백만 원)')
plt.legend()
plt.show()위 코드를 실행하면 다음과 같은 결과가 출력되죠.
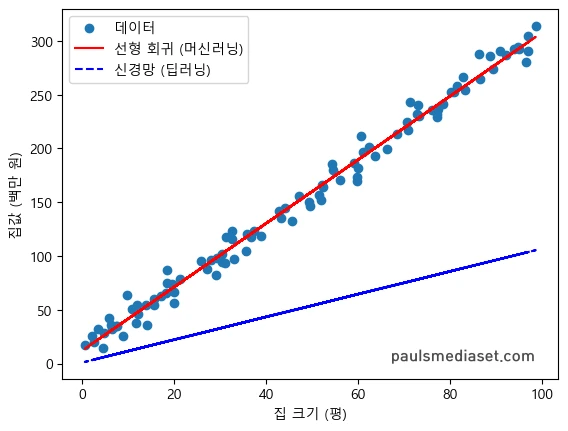
결과는 머신러닝과 딥러닝 모두 선형적인 관계가 뚜렷하게 나타났어요. 그런데, 기준 데이터와 비교하면 딥러닝보다는 머신러닝이 원본 데이터에 가깝게 나타났어요. 이유가 뭘까요?
오늘은 여기까지만 정리하고 다음에 또 기회가 되면 이러한 결과가 나타난 이유와 딥러닝의 구현 방법에 대해 좀 더 자세한 내용을 다뤄볼게요.
- 한국어 LLM 모델과 토크나이저 교체에 따른 영향 – 나만의 모델 만들기 #5
- Custom model 생성 및 safetensors 저장 방법 – 나만의 모델 만들기 #4
- SentencePiece 토크나이저 정의와 HF 래핑 – 나만의 모델 만들기 #3
- Gemini CLI로 텍스트를 JSON으로 변환하기 – 코드 없이 구현하기 #1
- ComfyUI 간단한 사용 방법 – 워크플로우 구성, 이미지 생성 가이드 #1