지난 글에서는 한국어 AI를 구축하기 위해서, HyperCLOVA의 토크나이저를 GPT-2 Medium 모델에 이식하는 과정을 정리해 봤어요. 한국어에 특화된 토크나이저를 적용함으로써 한국어 문장 구성에 대한 학습 효과를 높이려는 시도였죠. 오늘은 그 실험 결과와 한계, 그리고 결국 학생 모델을 변경하게 된 이유를 정리해 보려 합니다.
소형 언어 모델로 한국어 AI 만들기
GPT-2 Medium 기반 한국어 AI
GPT-2 Medium 모델은 3.5억 파라미터 수준으로, 소형 모델보다는 표현력이 뛰어나면서도 개인 로컬 PC 환경에서 학습 가능한 범위라 생각으로 학생 모델로 선정했었어요. 또, 가능하다면 한국어 학습을 완료한 후에는 멀티모달로 확장할 계획이었죠. 때문에, 너무 작은 모델은 멀티모달 확장은 한계가 있을 거라 생각했기 때문에 너무 작은 모델은 제외하고 한 단계 위한 medium 모델을 선택했죠.
HyperCLOVA의 토크나이저를 이식한 후, 우선 지식 증류 전에 기본적인 한국어 문장 생성 능력 향상에 초점을 맞춰 학습을 시작했습니다. 교사 모델로 HyperCLOVA를 선택한 이유는 너무도 많지만 한국어 기반 대형 언어 모델 중 유일하지 않을까요? 물론, 학계나 관련 산업 분야에 유명한 모델이 있을 수는 있으나, 일반인의 위치에서 유일한 한국어 대형 언어 모델이 아닐까 싶었어요. 때문에 한국어 AI 모델 중에서 가장 성능이 뛰어나다고 할 수도 있고요.
이러한 교사 모델의 토크나이저를 정확하게 이식할 수 있으면 학생 모델의 한국어 성능을 빠르게 향상할 수 있을 거라 예상했어요. 한국어 생성 데이터셋을 학습에 필요한 구조로 변경하고, 여러 epoch를 반복하며 성능을 측정했어요. learning rate나 관련 파라미터도 변경해 보면서 테스트를 했어요.
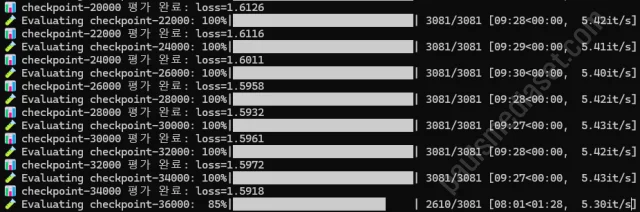
그러나 성능 향상은 없었다
문제는 아무리 학습을 반복해도 성능이 향상되지 않았다는 점입니다. perplexity(혼란도) 지표도 일정 수준 이하로 내려가지 않았고, 문장 구성 역시 여전히 부자연스러웠습니다. 다음과 같은 패턴이 반복되었습니다.
- 문법적으로 어색하거나 중간에 문장이 끊기는 현상
- 일관성 없는 어휘 선택
- 주어와 서술어 호응 문제
처음에는 learning rate, warm-up, optimizer 설정을 조정해 보기도 했고, 데이터 정제를 다시 해보기도 했지만 결과는 비슷했습니다. 시간만 소요됐죠. 사실 이 부분이 가장 중요한데, A100이상의 고사양 시스템이었다면 훈련도 빠르고 즉각적으로 반응할 수 있는 실행과 결과의 연속성을 갖을 수 있었겠지만, 그런 환경이 아닌 상황에서 이러한 시도는 다양한 시도를 할 수는 없다는 게 가장 큰 고민이었어요.
문제의 원인은 구조적 한계
결과적으로 여러 상황을 고려하여 정리해 본 문제의 원인은 다음과 같이 정리할 수 있었습니다.
- GPT-2의 구조 자체가 구형
- GPT-2는 기본적으로 영어 기반 BPE 구조에 최적화되어 있어, 비영어권 언어에 대한 학습 효율이 떨어집니다. 물론 토크나이저를 이식했지만, 여전히 내부 모델 구조는 2019년 기준의 설계에 머물러 있어 한국어 문장 구조를 잘 포착하지 못했습니다.
- 사전 지식 없음에서 오는 학습 난이도
- GPT-2는 한국어에 대한 사전 학습이 전혀 없는 상태이기 때문에, 완전히 처음부터 문장 구조와 문법을 학습해야 했습니다. 이 경우 학습이 길어지고 안정화되기까지 많은 데이터와 시간이 필요합니다. 사실 이 부분이 가장 부담이었죠. 로컬 환경에서는 한계가 분명했으니까요.
- 파라미터 수 대비 학습 데이터 부족
- Medium 모델은 단순히 크기만 키운 모델이기 때문에, 학습 데이터가 충분하지 않으면 성능이 오히려 Base 모델보다도 더 안 나올 수 있습니다. 모델 용량이 클수록 일반화가 느리고 과적합 위험도 증가하기 때문입니다. 아마도, GPT-2 기반 한국어 AI 모델들은 GPT-2 base 모델을 활용했을 듯 합니다.
학생 모델 교체 – Qwen3 0.6B로 전환
이러한 문제로 인해 결국 학생 모델을 변경하기로 결정했습니다. 새롭게 선택한 모델은 Qwen3 0.6B입니다. 이 모델은 GPT-2와 몇 가지면에서 두드러진 차이가 있더군요.
- 한국어 포함 다국어 사전 학습: 한국어에 대한 기초적인 문장 구조와 문법을 이미 일정 부분 학습하고 있음.
- 최신 구조의 Transformer 적용: RoPE, SwiGLU, Flash Attention 등 GPT-2에는 없는 최신 구조를 채택해 학습 효율이 높음.
- 크지 않은 파라미터 규모: 6억 파라미터로서 충분한 표현력을 가지면서도 여전히 로컬 환경에서 학습 가능함.
사실, 한국어 AI, 즉 한국어 전용 대형 언어 모델이 있다면 그냥 사이즈만 줄여서 뭔가를 만들어 볼 수 있었을 거예요. 저 같은 관심이 있는 사람이나 단체들 모두 뭔가를 다양하게 만들어 낼 수 있었겠죠. 하지만, 가장 기본적인 한국어라는 장벽이 대형 언어 모델이 없다는 거예요. 외국 것을 차용해서 뭔가를 해야 한다고 생각하다 보니 이것저것 고민할 게 많아지는 거죠. 또 최근 Meta처럼 자신들의 사업 방향성이 변경되면 속수무책이 되는 거죠. 한국어 대형 언어 모델이 없이 뭔가를 한다는 건 모래성을 쌓고 있는 거나 다름이 없다고 생각해요.
하여간, 다시 한국어 기초부터 학습을 하고 있어요. Qwen이 다국어 모델이기는 하지만, 여전히 한국어 전용 모델은 아니니까요. 보다 더 유연하고 유능한 한국어 능력을 갖추기 위해서 또다시 처음부터 실행하고 있어요.
다음에는 한국어 AI가 될 수 있는 성능 향상 결과를 정리해 볼 수 있기를 바라봅니다.
- HyperCLOVA의 Tokenizer로 한국어 AI 생성하기 – 생성형 AI 만들기 #1
- Google AI Gemini API 무료 사용 방법과 OpenAI와 차이점 #1
- OpenAI API 요금은 어떻게 계산될까? 토큰 개념과 tiktoken 활용 #1
- OpenAI API를 활용한 새해 운세 프로그램 #1 – 사주팔자 년주 세우기