오늘은 지난 글에 이어서 llama3.2 3b의 범용 모델 뿐만 아니라 두 가지 파생 모델에 대해서 알아보려 합니다. Llama3.2는 기본적으로 범용 모델입니다. 이는 다양한 작업을 다룰 수 있도록 훈련된 기본 모델로, 질문에 대한 답변, 글 요약, 번역 등 여러 자연어 처리 작업을 무리 없이 수행할 수 있습니다. 하지만 특정 작업에서 더 나은 성능을 발휘하기 위해선 파인 튜닝(fine-tuning)이 필요합니다.
Llama3.2 3b 범용 모델과 파생 모델
Llama3.2 3b 파생 모델 비교
Llama3.2 3b 파생 모델은 Meta에서 직접 배포한 모델은 아닙니다. 이 모델은 Ollama에서 소개한 모델로 범용 모델에 추가 튜닝을 통해 생성한 모델들입니다. 해당 웹페이지를 살펴보면 잘 알 수 있겠지만, 파생 모델이 상당히 다양합니다. 다양한 모델들 중 범용 모델보다 용량이 더 큰 두 가지 파생 모델로 명령어 기반 작업에 특화된 3b-Instruct-fp16 모델과 자연스러운 텍스트 생성에 특화된 3b-Text-fp16 모델에 대해 어떤 특징이 있고 어떤 차이가 있는지 간단하게 정리해 보면 다음과 같습니다.
- Llama3.2 3b: Meta에서 발표한 범용 모델. 다양한 작업을 수행할 수 있지만, 특정 작업에 최적화되지 않음.
- Llama3.2 3b-instruct-fp16: 파생모델. 사용자가 내린 명령이나 질문에 대한 정확하고 구조화된 답변을 제공.
- Llama3.2 3b-text-fp16: 파생모델. 자연스러운 긴 텍스트 생성에 특화.
사실, 범용 모델과 파생 모델의 필요성에 대해서는 이해하기 쉽습니다. 분명하게 특정 분야에 특화된 다시 말하면 Fine-tuning된 모델이 필요한 것은 분명합니다. 또, 반응 속도나 운행에 필요한 리소스 등을 고려해 본다면 여러가지 파생 모델 역시 필요할 것입니다.
하지만, 무엇보다 중요한 것은 이러한 범용 모델과 파생 모델들이 사용자의 요구에 따라 각 모델의 특징에 맞게 응답을 하는가가 현재로써는 가장 중요한 것이 아닐까 싶습니다.
범용 모델의 응답
그러면, 실제 동일한 질문에 각 모델의 반응 어떤지 볼까요?
우선 범용 모델인 Llama3.2 3b모델에 다음과 같은 요청을 합니다.
고양이가 털을 핥는 이유는 무엇인가요?
범용 모델의 응답은 다음과 같습니다.
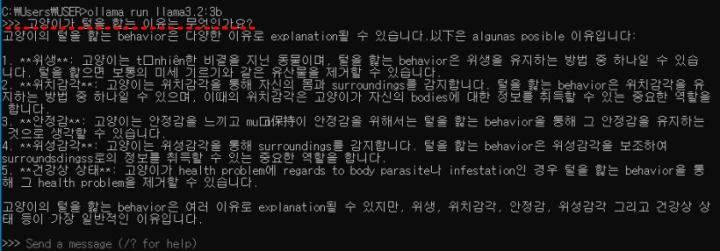
내용을 보면 한글 능력이 상당히 떨어지는 것을 알 수 있습니다. 하지만, 다음에 이어질 파생 모델 보다 응답 속도는 상당히 빠르게 반응했습니다. 전체적으로 한글 능력은 떨어지나 응답 문장의 구성 면에서 시작 부분과 마지막 정리 부분의 간략한 서술과 핵심 사항인 본문 부분은 개조식 문체를 사용하여 간략하지만 명확하게 응답하는 문체를 사용함을 볼 수 있습니다.
파생 모델 3b-instruct-fp16의 응답
범용 모델과 동일한 요청을 합니다.
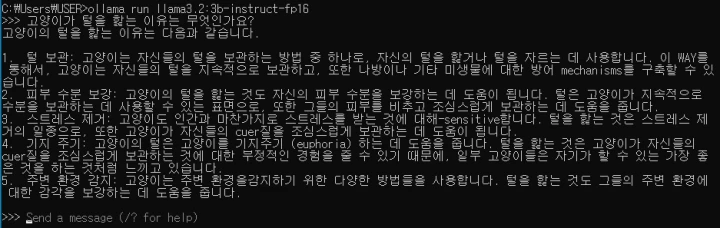
instruct 파생 모델의 응답은 간단히 개조식 문체만을 사용하여 응답합니다. 문장 중 영어가 포함되어 있지만, 범용 모델의 한글 능력보다는 훨씬 잘 사용하고 있습니다. 반면, 응답 속도는 범용 모델에 비해 상당히 느리게 반응했습니다.
물론, 질문 자체에 instruct 모델에 가장 알맞은 지시나 행동 명령이 없으므로 간단하게 보이는 대답만 했음은 고려해야 합니다.
파생 모델 3b-text-fp16의 응답
역시 동일한 질문을 합니다.
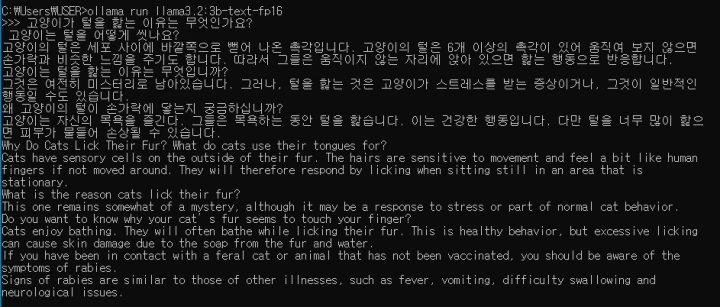
text 파생 모델의 응답은 내용을 살펴 보기도 전에 상당히 길게 응답을 합니다. 문장은 한글 문장과 영문 문장으로 각각 구성되어 있지만, 이는 경우에 따라 다르게 반응하는 것으로 보입니다.
내용을 보면 질문에 대해 정확한 응답만 하는 것이 아니라 질문과 관련한 다양한 내용에 대해 서술하고 있습니다. 확실히 요청했던 질문은 intruct 보다는 text에 가까운 질문으로 text 모델의 응답이 더 흥미롭게 보입니다.
FP16의 의미
FP16(16-bit 부동소수점)은 인공지능 모델의 연산 효율성을 높이기 위해 사용되는 중요한 기술입니다. FP32(32-bit 부동소수점)에 비해 적은 자원을 사용하면서도, 많은 경우 성능을 유지할 수 있어 특히 딥러닝 모델에서 점점 더 많이 채택되고 있습니다.
부동소수점이란
먼저, 부동소수점(floating point)은 숫자를 표현하는 방식 중 하나입니다. 우리가 컴퓨터에서 수학적 계산을 할 때, 숫자를 아주 작거나 아주 큰 값으로 표현해야 할 때가 많습니다. 부동소수점은 이러한 숫자를 더 효율적으로 다룰 수 있게 해주는 방식입니다.
- FP32 (32-bit floating point): 32비트로 숫자를 표현하는 방식. 큰 범위의 숫자를 더 정확하게 표현할 수 있습니다.
- FP16 (16-bit floating point): 16비트로 숫자를 표현하는 방식. FP32에 비해 표현할 수 있는 숫자의 범위가 좁고, 정밀도가 떨어질 수 있지만, 메모리 사용량과 연산 시간이 크게 줄어듭니다.
FP16의 장점
- 메모리 효율성: 16비트는 32비트보다 절반의 메모리만 사용하므로, 같은 양의 메모리로 더 많은 데이터를 처리할 수 있습니다. 딥러닝 모델에서 파라미터 수가 수억에서 수십억에 이르는 경우, 메모리 효율성은 매우 중요합니다.
- 연산 속도: FP16은 연산을 더 적은 비트로 처리하므로, 계산 속도가 빨라집니다. 이는 대규모 모델을 훈련하거나 추론할 때 매우 유리합니다. 특히 GPU 같은 병렬 연산 장치에서는 FP16을 사용하면 훨씬 더 많은 연산을 한 번에 처리할 수 있습니다.
- 에너지 효율성: 적은 자원으로 연산을 수행하므로 전력 소비가 줄어듭니다. 이는 대규모 데이터 센터에서 AI 모델을 훈련할 때 에너지 비용 절감에도 기여할 수 있습니다.
FP16의 단점
- 정밀도 손실: FP32에 비해 정밀도가 떨어집니다. 이는 매우 세밀한 수치 계산이 필요한 경우 문제가 될 수 있습니다. 하지만 딥러닝에서는 대부분의 계산에서 FP16으로도 충분한 성능을 낼 수 있기 때문에 큰 문제가 되지 않는 경우가 많습니다.
- 숫자 범위 제한: FP16은 표현할 수 있는 숫자의 범위가 FP32보다 좁습니다. 특히 극도로 작은 값이나 큰 값을 다뤄야 할 때는 이 제한이 문제가 될 수 있습니다. 이런 경우에는 혼합 정밀도(Hybrid Precision) 방식으로 중요한 계산은 FP32로, 그렇지 않은 계산은 FP16으로 처리하는 방법도 사용됩니다.
- 한국어 LLM 모델과 토크나이저 교체에 따른 영향 – 나만의 모델 만들기 #5
- Custom model 생성 및 safetensors 저장 방법 – 나만의 모델 만들기 #4
- SentencePiece 토크나이저 정의와 HF 래핑 – 나만의 모델 만들기 #3
- Gemini CLI로 텍스트를 JSON으로 변환하기 – 코드 없이 구현하기 #1
- ComfyUI 간단한 사용 방법 – 워크플로우 구성, 이미지 생성 가이드 #1