지금까지 라마 파인 튜닝을 위한 모델을 찾았고, 이 모델이 정상 작동하는지 확인하기 위한 방법으로 Ollama 플랫폼으로 생성하여 Docker를 통해 질문과 답변을 받아 보는 방식 등을 확인해 봤습니다. 또, 파인 튜닝에 꼭 필요한 데이터셋에 대해 알아봤습니다. 관련 글은 아래와 같으니 필요하신 분들은 참고하시고요.
- llama fine tuning 방법 #2 – 목표 설정과 Dataset
- llama fine tuning 방법 #1 – gguf 파일 변환과 Ollama 모델 생성
- 데이터셋(dataset) 생성으로 Llama 3.1 파인 튜닝하기
라마 한글 파인 튜닝 (Llama fine tuning)
자, 이제 파인 튜닝 본론으로 가보겠습니다.
원체 오래된 PC에 파인 튜닝이 하려니 여러 가지 걸리는 사항들이 있는데요, 우선 PC 사양은 아래와 같습니다.
프로세서: AMD Ryzen 3 3300X 4-Core Processor 3.79 GHz
RAM : 16.0GB
그래픽: NVIDIA GeForce GTX 1650
Llama 모델 중에서도 llama 3.2 1B를 선택한 이유가 처음에는 3B 모델을 튜닝해 보고 싶었으나 워낙 낮은 사양이다 보니 3B 모델은 시작도 안되던 상황이었습니다.
모델 로딩 준비
자 그럼 python 코드를 작성해 보겠습니다. 우선 타깃 경로에 hugging face에서 다운로드한 파일(mode.safetensors, config.json, tokenizer.json 등)을 넣어둡니다.
아래와 같이 상기 경로에서 model과 tokernizer를 읽어 옵니다.

AutoModelForCausalML 클래스를 사용하는 이유는 텍스트 생성 등 언어 생성에 주로 사용되는 모델 아키텍처입니다. 이외에 Hugging face 라이브러리의 AutoModelForSequenceClassification 클래스 등도 자주 사용됩니다.
조금이라도 메모리 관리에 영향이 있을 것 같아서 use_safetensors=True로 지정하여 활성화해 봤습니다. 뿐만 아니라 아래 코드 역시 메모리 사용량을 최소화하기 위해 설정해 둡니다.

gradient_checkpointing_enable()은 메모리 사용량을 줄이기 위해서 중간중간 데이터를 저장하지 않고 필요할 때만 재계산을 수행하도록 해주는 메서드입니다. 또, use_cache를 비활성화해서 학습 중 계산된 결과를 개시하지 않도록 하여 메모리 사용량을 줄이도록 합니다.
데이터셋 준비
우선, 이전 글에서 다운로드해 둔 한글 데이터셋 중에서 질문-답변 쌍으로 구성된 SFTlabel.json 파일들을 로드에 둡니다. 그런 후 이들을 토크나이저로 변화하여 커스텀 데이터셋을 생성하기 위해 파이토치 패키지에서 제공하는 Dataset 클랙스를 상속해야 합니다.
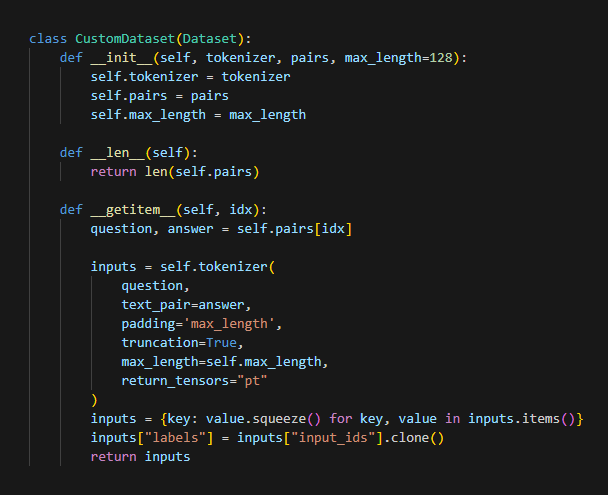
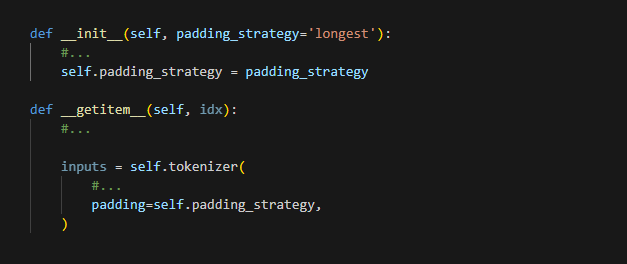
지금 생각해 보면 padding 옵션을 좀 더 자유롭게 했어야 하지 않았나 싶습니다. max_length의 경우 텍스트의 길이가 짧은 경우면 메모리 사용 효율이 떨어질 수 있기 때문입니다. 예를 들면 아래와 같이 말이죠.
그 외는, 앞의 코드 아래 부분에서 labels를 input_ids 클론으로 설정합니다. 이렇게 하는 이유는 모델이 입력된 텍스트를 보고 그다음에 올 단어를 쉽게 예측하도록 하기 위함입니다. 즉, 모델이 스스로 입력 문장을 이해하고, 그 문장 다음에 올 수 있는 문장을 더 정확하게 만들어 낼 수 있도록 학습 준비를 해 두는 단계라고 할 수 있습니다.
파인 튜닝 설정
자, 그러면 이제 실제 학습을 설정하는 부분을 작성해 보도록 하겠습니다. 이번 경우에 Hugging face의 transformers 라이브러리에서 제공하는 TraininArguments 클래스를 사용했습니다. 아래와 같이 패키지 import가 필요합니다. (Trainer 부분은 실행 시 사용합니다.)
from transformers import Trainer, TrainingArguments
TraininArguments 클래스를 통해 학습 방법, 리소스 사용 설정 그리고 결과 저장 위치를 설정합니다. 아래 코드와 같이 말이죠.
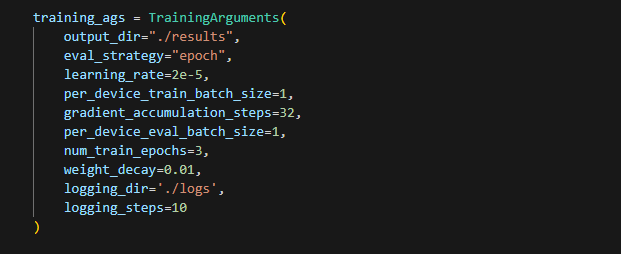
학습 설정
학습 설정 관련은 eval_strategy, learning_rate, num_train_epochs, weight_decay부분입니다. 예를 들어 위 코드에서 eval_strategy=”epoch”로 설정했는데, 이것은 학습 데이터 전체를 한번 학습한 후에 평가를 실행하다는 의미입니다. eval_strategy를 통해 가능한 설정 값은 아래와 같이 3 종류입니다.

리소스 관리
하드웨어와 메모리 관련 부분인 리소스 관리에 해당하는 옵션은 per_device_train_batch_size, gradient_accumulation_steps, per_device_eval_batch_size입니다.
변수명이 직관적으로 표현되어 있지만 per_device_train_batch_size가 1로 설정된 이유는 GPU나 CPU(디바이스) 하나가 한 번에 학습할 데이터 묶음의 크기를 설정합니다. 다시 말하면 한번 학습할 때 몇 개의 데이터를 동시에 처리할지를 설정하는 옵션입니다. 제 PC 사양으로는 불가피한 선택이었고요.
나머지는 입출력 정보 로드 및 저장과 관련된 부분입니다.
이 부분의 코드는 학습 능력과 리소스 그리고 실제 수행 속도와 너무나 밀접한 관계가 있는 부분입니다. epoch를 3 이상 설정이 불가했던 점도 아쉬움이 큰 부분이기도 하지만, batch size로 마음대로 조절할 수 없을 만큼 낮은 사양에서 파인 튜닝을 진행해야 하는 환경이 좀 답답했죠. 어떤 분들은 구글 코랩을 이용해서 하신다고 하는데, T4 GPU를 사용한다고 해도 비용이 적지는 않을 것 같습니다. 학교나 직장에서 대형 컴퓨팅을 자유롭게 활용할 있는 환경이라면 모를까 말이죠.
하여간, 여러 번에 걸쳐 옵션 값을 변경한 결과 아래와 같이 파인 튜닝이 시작되었습니다.

위 그림에는 나오지 않았지만, 총 실행 시간은 80시간이 예상된다고 나옵니다. 4일을 기다려야 결과를 볼 수 있다는 거죠. 실행 중간 오류 없이 결과까지 잘 진행될지 불안하기도 하지만 기대 반 걱정 반으로 기다려 봐야겠습니다.
그럼, 결과가 나오면 결과를 검토 정리해 보겠습니다.
- 한국어 LLM 모델과 토크나이저 교체에 따른 영향 – 나만의 모델 만들기 #5
- Custom model 생성 및 safetensors 저장 방법 – 나만의 모델 만들기 #4
- SentencePiece 토크나이저 정의와 HF 래핑 – 나만의 모델 만들기 #3
- Gemini CLI로 텍스트를 JSON으로 변환하기 – 코드 없이 구현하기 #1
- ComfyUI 간단한 사용 방법 – 워크플로우 구성, 이미지 생성 가이드 #1
llama fine tuning 방법 시리즈
- llama fine tuning 방법 #1 – gguf 파일 변환과 Ollama 모델 생성
- llama fine tuning 방법 #2 – 목표 설정과 Dataset
- llama 3.2 1b 파인튜닝으로 한국어 능력 향상시키기 #4