며칠 전 Meta에서 Llama 3.2를 발표했습니다. Llama 3.1을 발표한지 얼마 되지도 않았는데, 또 다른 버전이 발표했습니다. Meta가 상당히 적극적으로 움직이고 있는 모양새입니다. 이번 발표한 Llama3.2는 어떤 변화가 있는지 알아보고 발표된 세부적인 모델들이 어떻게 구성되어 있는지도 살펴보도록 하겠습니다.
* llama 3.2 3b 설치와 관련해서는 llama 3.1 8b 설치와 관련한 이전 글을 참고해 주세요.
Llama 3.2와 Llama 3.1의 차이점
Llama 3.2는 이전 버전인 Llama 3.1과 비교했을 때 다양한 측면에서 변화되었습니다.
- 학습 데이터의 규모와 다양성: Llama 3.2는 Llama 3.1보다 훨씬 풍부하고 다양한 데이터를 학습했습니다. 이로 인해 언어의 뉘앙스, 복잡한 문맥, 문화적 맥락까지 더욱 깊이 이해할 수 있게 되었고, 사용자 의도에 맞는 자연스럽고 유용한 답변을 제공할 수 있습니다.
- 모델 구조의 개선: Llama 3.1은 기존 Transformer 아키텍처를 주로 사용했지만, Llama 3.2는 더욱 효율적인 Attention 메커니즘을 도입했습니다. 이를 통해 정보 처리 속도가 높아졌으며, 긴 문맥을 처리할 때에도 일관성 있고 정확한 결과를 낼 수 있게 되었습니다.
- 최적화된 파라미터 활용: Llama 3.2는 더 적은 파라미터로도 Llama 3.1과 유사하거나 더 우수한 성능을 발휘합니다. 이러한 최적화 덕분에 모델 실행 시 필요한 자원과 메모리 사용량이 감소하여, 실제 응용에서 더 빠르고 효율적인 추론이 가능합니다.
- 메모리 관리 및 처리 능력: 메모리 관리 기술이 개선되어 Llama 3.2는 Llama 3.1에 비해 더 많은 입력 토큰을 동시에 처리할 수 있습니다. 이를 통해 긴 문장이나 복잡한 문단도 원활하게 다룰 수 있어, 자연어 생성 작업에서 더 긴 문장을 자연스럽게 이어가거나 방대한 분량의 문서를 요약하는 데 탁월합니다.
- 정교한 미세 조정 능력: 훈련 과정에서의 미세 조정이 정교해진 Llama 3.2는 특정 작업에 대한 적응력이 크게 향상되었습니다. 번역, 요약, 질문-답변 등 다양한 분야에서 Llama 3.1보다 더욱 전문화된 성능을 발휘할 수 있습니다.
물론 이러한 것들은 실제 사용자 입장에서는 또 다른 반응으로 나타날 것입니다. 사용 환경과 조건이라는 게 동일하게 하는 것도 어렵기 때문일 거예요. 그냥 이런 변화가 있었구나 정도로 넘어가고 실제로 우리는 두 가지 버전에서 같은 요청에 대해 어떤 응답을 하는가가 중요하지 싶습니다.
Llama 3.2 3b 모델과 Llama 3.1 8b 모델의 비교
여기에서 “b”는 “billion”을 의미하여 “3b” 30억개, “8b”는 80억개 ‘파라미터를 갖는다’라는 의미입니다. 즉, 모델 이름으로만 본다면 라마 3.2 3b 보다 라마 3.1 8b의 파라미터가 더 크다는 것을 알 수 있습니다. 때문에 해당 모델의 용량도 8b에 비해 3b는 절반 이하도 작아져서 2Gb 정도에 불과합니다.
하지만, 이러한 파라미터 차이에도 불구하고 라마 3.2 3b의 성능이 기존 3.1 8b의 성능을 뛰어 넘는다고 기대하고 있는데요, 과연 그러한지 공통 질문으로 한 번 비교해 보겠습니다.
먼저 라마 3.1 8b에게 “한국어를 이해해?” 라고 질문합니다. 아래 그림 처럼 엉뚱한 대답을 하기도 합니다. 처음에는 일본어로 답했고, 두 번째는 답변이 어색합니다. 세 번째 시도에서 정확하게 답변하는 모습을 보입니다.
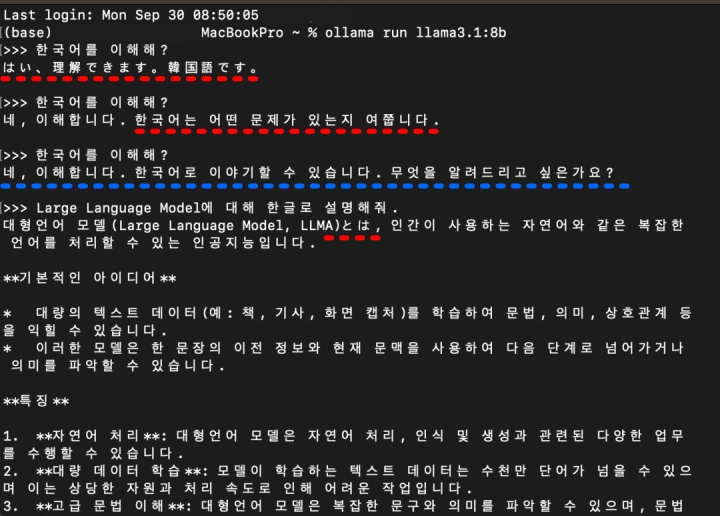
이후 설명인 필요한 질문으로 Large Language Model (LLM)에 대해 설명을 요청했습니다. 위 그림에서는 잘 보이지 않으므로 전체 내용은 아래를 참고해 주세요.
Last login: Mon Sep 30 08:50:05
(base) MacBookPro ~ % ollama run llama3.1:8b>>> 한국어를 이해해?
はい、理解できます。韓国語です。>>> 한국어를 이해해?
네, 이해합니다. 한국어는 어떤 문제가 있는지 여쭙니다.>>> 한국어를 이해해?
네, 이해합니다. 한국어로 이야기할 수 있습니다. 무엇을 알려드리고 싶은가요?>>> Large Language Model에 대해 한글로 설명해줘.
대형언어 모델(Large Language Model, LLMA)とは, 인간이 사용하는 자연어와 같은 복잡한 언어를 처리할 수 있는 인공지능입니다.기본적인 아이디어
- 대량의 텍스트 데이터(예: 책, 기사, 화면 캡처)를 학습하여 문법, 의미, 상호관계 등을 익힐 수 있습니다.
- 이러한 모델은 한 문장의 이전 정보와 현재 문맥을 사용하여 다음 단계로 넘어가거나 의미를 파악할 수 있습니다.
특징
- 자연어 처리: 대형언어 모델은 자연어 처리, 인식 및 생성과 관련된 다양한 업무를 수행할 수 있습니다.
- 대량 데이터 학습: 모델이 학습하는 텍스트 데이터는 수천만 단어가 넘을 수 있으며 이는 상당한 자원과 처리 속도로 인해 어려운 작업입니다.
- 고급 문법 이해: 대형언어 모델은 복잡한 문구와 의미를 파악할 수 있으며, 문법 구조의 이해도 높습니다.
장점
- 고차원적인 상호작용: 사용자는 더 심층적으로 의미를 교환하고 정보를 교류하기 위해 모델을 통해 의사소통을 할 수 있습니다.
- 빠른 답변 및 해결책 제공: 대형언어 모델은 대량의 지식과 정보에 접근할 수 있으며, 문제 해결에 도움이 될 것입니다.
단점
- 인터넷 연결 요구: 일부 기능이 인터넷 연결을 필요로 할 수 있습니다.
- 처리 시간 및 자원: 모델 학습 및 처리 시 소요되는 자원과 시간은 상당합니다.
대형언어 모델의 개발은 인공지능 연구와 실용적인 사용 사이의 균형점에서 이뤄지는 분야입니다.
>>> Send a message (/? for help)
이제 llama 3.2 3b에게도 같은 질문을 합니다. 먼저 “한국어를 이해해?”라고 물었습니다. 대답은 역시 100% 매끄럽지 못합니다. 하지만, 라마 3.1 8b에 비해서 문제될 것은 없어 보입니다. 이어서 구체적인 설명이 필요한 라마 3.1에서 했던 동일한 질문을 합니다.
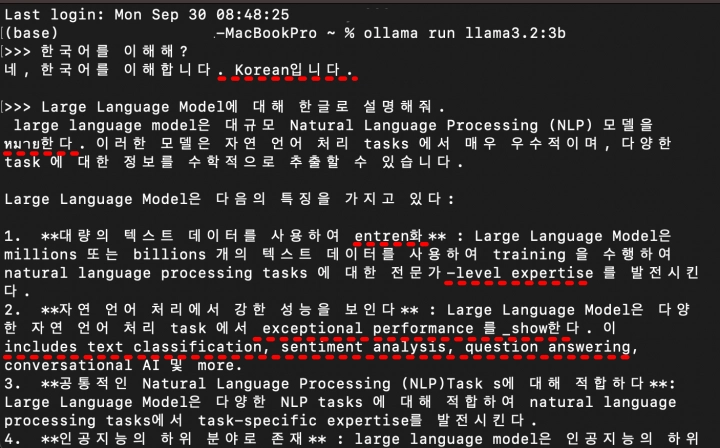
위 그림으로는 전체 내용을 알 수 없으므로, 구체적은 아래를 참고해 주세요.
Last login: Mon Sep 30 08:48:25
(base) MacBookPro ~ % ollama run llama3.2:3b>>> 한국어를 이해해?
네, 한국어를 이해합니다. Korean입니다.>>> Large Language Model에 대해 한글로 설명해줘.
large language model은 대규모 Natural Language Processing (NLP) 모델을 หมาย한다. 이러한 모델은 자연 언어 처리 tasks 에서 매우 우수적이며, 다양한 task 에 대한 정보를 수학적으로 추출할 수 있습니다.Large Language Model은 다음의 특징을 가지고 있다:
- 대량의 텍스트 데이터를 사용하여 entren화 : Large Language Model은 millions 또는 billions 개의 텍스트 데이터를 사용하여 training 을 수행하여 natural language processing tasks 에 대한 전문가-level expertise 를 발전시킨다.
- 자연 언어 처리에서 강한 성능을 보인다 : Large Language Model은 다양한 자연 언어 처리 task 에서 exceptional performance 를_show한다. 이 includes text classification, sentiment analysis, question answering, conversational AI 및 more.
- 공통적인 Natural Language Processing (NLP)Tasks에 대해 적합하다:
Large Language Model은 다양한 NLP tasks 에 대해 적합하여 natural language processing tasks에서 task-specific expertise를 발전시킨다.- 인공지능의 하위 분야로 존재 : large language model은 인공지능의 하위 분야로 존재한다. 자연 언어 처리 및 deep learning techniques에 대한 지식이 필요하다.
Large Language Model은 많은 ứng dụng에 사용할 수 있으며, 다음을 포함한다:
- Virtual assistants: Large Language Model은 virtual assistants 에서 사용되어 natural language input을 이해하고 적절한 response를 제공합니다.
- Content generation: Large Language Model은 content generation task에서 사용하여 natural language text를 생성합니다.
- Language translation: Large Language Model은 language translation task 에서 사용하여 Natural language text를 다른 언어로 번역합니다.
- Conversational AI: Large Language Model은 conversational AI 에서 사용되어 conversation 을 이해하고 적절한 response를 제공합니다.
Large Language Model은 다양한 application 에 사용할 수 있으며, 자연 언어 처리 및 deep learning techniques에 대한 지식이 필요하다.
Send a message (/? for help)
위와 같이 각 모델에 대해 요청과 답변 내용을 비교하여 3가지 중요 지점에 대해 분석 정리해 보도록 하겠습니다.
한글 능력 수준 비교
- Llama 3.1 8b 모델:
- 첫 번째, 두 번째 질문에서 한국어를 완벽하게 이해하지 못하고 일본어로 답하거나 부자연스러운 표현을 사용했습니다.
- 세 번째 시도에 이르러서야 제대로 된 한국어 응답을 제공했습니다.
- LLM에 대한 한국어 설명은 대부분 적절하지만, 일부 문장 구조에서 자연스럽지 않은 부분이 확인되었습니다.
- Llama 3.2 3b 모델:
- 첫 번째 질문에 바로 한국어로 응답하였으며, 상대적으로 더 매끄러운 한국어 사용을 보여주었습니다.
- LLM에 대한 설명에서도 대부분 자연스럽고 명확한 한국어를 사용했지만, 일부 외국어 혼용 부분과 영문 표현으로 한국어 능력은 상당히 떨어지는 것으로 보입니다.
텍스트 처리 능력 비교
- Llama 3.1 8b 모델:
- LLM에 대한 설명은 대체로 이해하기 쉬웠지만, 긴 문장 구조에서 중복 표현과 불필요한 설명이 일부 확인되었습니다.
- 개념을 전달하는 데 있어 어느 정도 전문적인 용어를 사용하지만, 전체적으로 이해에 도움이 되지 않는 불필요한 내용도 포함되어 있습니다.
- Llama 3.2 3b 모델:
- LLM에 대한 설명에서는 더욱 다양한 NLP 태스크와 응용 분야를 포함하여 세부적으로 설명합니다.
- 문장 구조는 더 간결하고 집중적이지만, 일부 여러 외국어와 영어 단어 등과의 혼용으로 인해 혼란스럽게 문장을 작성하고 있습니다.
Llama 3.2 3b 모델은 더 세부적이고 다양한 정보를 제공하며, Llama 3.1 8b 모델보다 더 높은 수준의 텍스트 처리 능력을 보입니다. 그러나 3.2 모델에서 일부 영문 표현의 혼용이 한국어 독자에게는 다소 불편할 수 있습니다.
요청 사항 처리 능력 비교
- Llama 3.1 8b 모델:
- 처음에는 부정확한 한국어를 제공하거나 일본어로 답하는 등 요청 사항에 대한 일관성이 떨어졌습니다.
- 여러 차례 시도 후에야 요청 사항을 정확하게 처리하는 모습을 보였습니다.
- Llama 3.2 3b 모델:
- 요청 사항에 대해 첫 시도부터 적절하게 처리하며 한국어 답변을 제공합니다.
- 전문 용어와 기술적 내용을 이해하고 처리하는 능력도 우수한 편입니다.
Llama 3.2 3b 모델은 요청 사항에 더 일관적이고 정확하게 반응하는 모습을 보여주며, 처리 능력에서도 Llama 3.1 8b 모델보다 뛰어납니다.
결론적으로, Llama 3.2 3b 모델은 파라미터 수가 적음에도 불구하고, 전반적인 능력에서 Llama 3.1 8b 모델을 뛰어넘는 성능을 보여주고 있습니다. 이러한 결과는 최신 알고리즘과 기술 발전을 통해 파라미터 수와 성능 간의 상관 관계가 과거보다 약해지고 있다는 것을 보여 주고 있습니다.
물론, 한국어 구현에 있어서는 두 모델 모두 아직 상당히 튜닝이 필요한 부분으로 보입니다. 물론 이것은 단 시간 내에 Meta에서 해결하지는 않을 것으로 보입니다.
오늘은 이것으로 마치고, 다음에는 llama 3.2 3b 모델로 instruct와 text 모델들에 대해서 살펴보도록 하겠습니다.