오늘부터는 연속하여 llama fine tuning(라마 모델 파인 튜닝)에 대해 이야기해 보려 합니다. 특히 llama fine tuning을 위한 사전 작업과 튜닝 과정을 자세하게 다뤄볼 예정입니다. 지금까지 llama 3.1, llama 3.2를 설치하고 실행과 관련한 여러 가지 이야기를 해봤으므로 이제 실제로 나만의 인공지능 모델을 구축하는 과정을 블로그에 남겨 보도록 하겠습니다.
Fine Tuning (파인 튜닝)을 위한 준비
fine tuning(파인튜닝)의 의미에 대해서는 여기에서 이야기하지 않고 방법에 대해 이야기를 해 보겠습니다. 제 생각에 Fine Tuning을 하기 위해서는 아래와 같이 크게 3가지 사항에 대해 준비가 되어야 합니다.
- 우선적으로 Fine Tuning을 하기 위해서는 먼저 인공지능 모델이 있어야 합니다. 당연한 이야기 입니다만, 기준 모델이 있어야 목적에 맞는 작업을 할 수 있겠죠. 저는 최신 Meta에서 발표한 Llama 3.2 1B모델을 기준으로 튜닝을 할 계획입니다. 제가 보유한 오래된 PC에서 실행되어야 하므로 덩치가 큰 모델은 실행할 수 없기 때문에 불가피한 선택입니다. 더 고성능의 모델을 다루고 싶은 마음은 큽니다만, 비용이 항상 문제가 됩니다.
- 두 번째로는 목적에 맞는 데이터셋(Dataset)이 있어야 합니다. ‘어떤 목적으로 파인 튜닝을 할 것인가’입니다. 현재 기준 제가 확인한 llama 3.2 1B의 한국어 수준은 상당히 부족합니다. 라마가 한글로 답변하는 중에 영어를 비롯한 외국어가 상당히 포함됩니다. 이를 개선하려는 목적으로 한글 데이터셋을 사용합니다.
- 세 번째로는 Fine Tuning을 위한 파이썬 프로그래밍입니다.
위 3가지에 대해 고려가 되었다면 이제 하나씩 실행하는 과정에 대해 이야기해 보겠습니다.
llama 3.2 1B 모델
앞선 글에서 Ollama 플랫폼을 통해 llama 모델을 쉽게 설치하고 실행하는 것에 대해 이야기했었습니다. 이렇게 설치된 모델을 Ollama를 통해 Fine Tuning 할 수 있으면 더없이 간편하고 좋을 것 같은데, 아직 그런 부분에 대해 정보가 없더군요. 어쩔 수 없이 ‘직접 Meta 공홈에서 모델을 다운해야 할까’라고 생각하며 정보를 찾아보던 중 파인 튜닝을 위해 가장 간단한 방법은 Hugging face에서 제공하는 모듈을 활용하는 방법에 대해 알게 되었습니다.
Hugging face 내에서 Meta에서 공식적으로 배포하는 모델을 제공하는 Meta Llama 페이지에서 llama 3.2 1B 모델을 다운로드합니다.
아래 3가지 파일은 필수입니다만, 저의 경우 해당 페이지에 있는 모든 파일을 다운로드했습니다.
- model.safetensors : 모델 가중치 파일로 학습된 파라미터를 포함합니다.
- tokenizer.json : 텍스트를 토큰으로 변환하는 데 사용됩니다.
- config.json : 모델의 구조, 하이퍼파라미터를 정의
llama 3.2 1B 모델 실행
다운로드한 모델이 정상적으로 작동하는 모델인지 확인해 봐야 합니다. 또는 기대했던 모델이 아니라 이미 너무 한국어를 잘하는 모델이면 파인튜닝 결과를 기대하기 어렵겠죠? 때문에 이 모델을 실행하여 요청에 응답을 잘하는지 한글 능력은 어떤지 확인해 봐야 합니다.
하지만, Ollama 플랫폼을 통해 설치한 것이 아니므로 이 모델을 실행하기 위해서는 또다시 이 모델과 대화할 수 있는 환경을 구축해 주어야 합니다. 간단하게 파이썬 코드로 확인해 볼 수도 있겠으나, 나중에 튜닝된 모델도 한눈에 비교해 보기 위해서는 Ollama를 이용한 WebUI 화면이 좋아 보였습니다.
Ollama 포멧으로 변환하기
다운로드한 llama 3.2 1B 모델은 model.safetensors 파일 형식으로 Ollama에서 지원하지 않으므로 지원하는 파일 포멧인 “.gguf” 파일 형태로 변환해야 합니다. 때문에 우선 이 파일 변환을 위해 llama.cpp 패키지를 설치해야 합니다.
cmd를 열고 다음과 같이 명령어를 입력합니다.
# github에서 zip 형태로 직접 다운로드도 가능합니다.
git clone https://github.com/ggerganov/llama.cpp
# 다운로드된 llama.cpp의 경로를 추가하여 설치합니다.
pip install -r [다운로드 위치]llama.cpp/requirements.txt
설치가 완료되었으면 다음의 명령어로 파일 변환을 명령합니다.
python “[llama.cpp 경로]/convert_hf_to_gguf.py” “[llama 3.2 1B 경로]/” –outfile [llama 3.2 1B 경로]/llama3.2-1b-orig.gguf –outtype f32
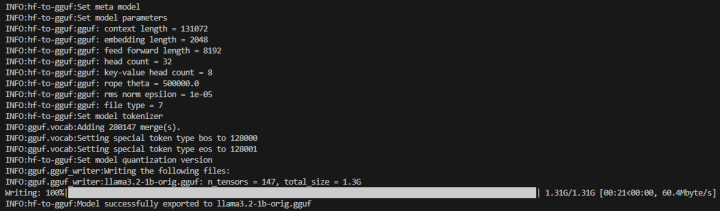
위의 과정을 통해 model.safetensors를 llama3.2-1b-orig.gguf로 변환했습니다.
‘convert_hf_to_gguf.py’의 사용법에 대해 알고 싶다면 다음과 같이 입력하면 됩니다.
python [llama.cpp 경로]/convert_hf_to_gguf.py -h
Ollama 모델 생성하기
모델 파일도 변환했으니 이제 Ollama에 변환된 모델을 이식하기만 하면 됩니다. Ollama 플랫폼에 이식하기 위해서는 “Create” 명령어를 사용하면 됩니다. 아래와 같이 Create 명령어 사용 방법에 대해 확인해 봅니다.
ollama create -h
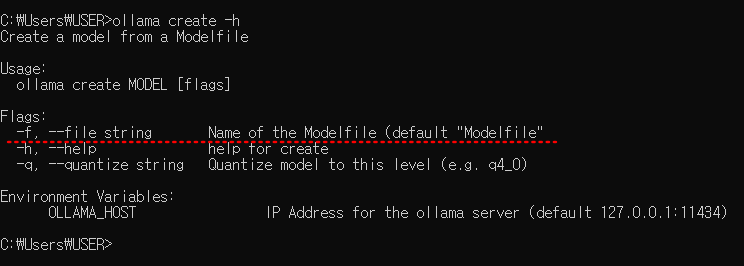
create 명령어는 모델 이름 다음에 flag 옵션을 사용해야 하는데 -f 옵션을 사용하는 경우 Modelfile이 필요하다고 합니다. ollama의 github의 modelfile.md를 보면 이 파일의 의미와 필요한 정보가 무엇인지 상세하게 나와있으니 참고하시고요, 저는 그저 modelfile이 필요하므로, 기존 ollama에 설치된 llama 3.2 1B 모델의 modelfile을 참고하도록 하겠습니다.
다시 cmd를 열고 다음 명령어를 입력하여 해당 모델의 Modelfile 내용을 확인합니다.
ollama show –modelfile llama3.2:1b
위와 같이 명령하면 ollama에 설치되었던 기존 llama3.2 1B 모델의 Modelfile 정보를 보여줍니다. 아래는 그중 일부입니다.
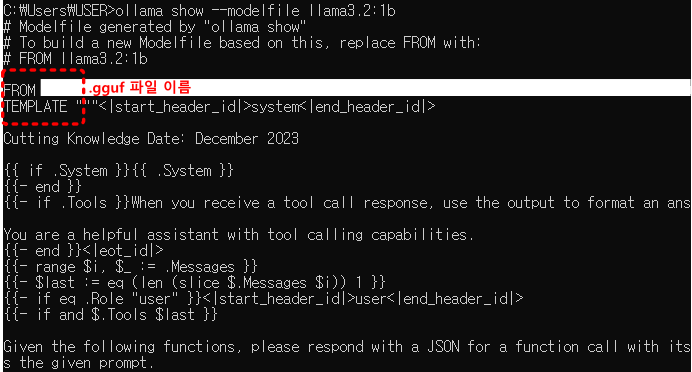
여러 정보가 나오는데, 간단하게 “From”, “Template” 정도만 작성해도 큰 무리는 없어 보이고요, 잘 모르겠다 싶으면 From 부분에만 자신이 변환했던 “파일명.gguf”로 하고 나머지는 동일하게 해도 테스트해 보는 수준에서는 문제가 없어 보입니다. 현재 모든 작업은 gguf 파일이 있는 동일 경로 내에서 이루어져야 합니다.
“Modelfile”은 확장자가 없다는 것에 유의하세요.
자, 그럼 이제 Modelfile도 만들었으니 “llama3.2-1b-orig.gguf” 모델을 Ollama 플랫폼으로 생성해 보겠습니다. cmd를 다시 열고 아래와 같이 명령합니다.
ollama create llama3.2-1b-orig -f ./Modelfile
# llama3.2-1b-orig 대신 자신이 변환한 .gguf 파일명을 입력합니다.
아래와 같이 출력이 나타납니다.
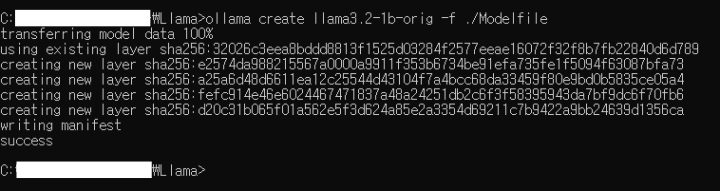
ollama를 통해 llama model을 설치할 때와 유사한 과정을 거칩니다. 그러면 잘 설치가 되었는지 다음과 같이 명령어를 입력합니다.
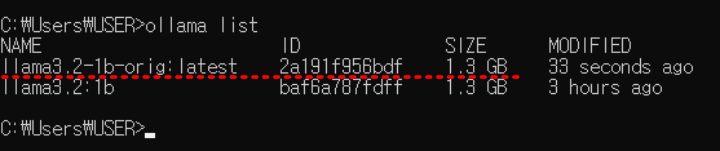
ollama list
아래와 같이 출력 내용을 확인합니다. 방금 전 설치한 “llama3.2-1b-orig”는 맨 뒤에 “:latest”가 추가되어 설치되었습니다. 바로 아래 “llama3.2:1b”는 기존 ollama model을 다운로드하여 설치한 모델입니다. 이 모델의 Modelfile 정보를 활용한 거죠.
자, 오늘은 여기까지 하고 다음 글에서 ollama에 설치된 “llama3.2-1b-orig”을 WebUI로 대화하여 현재 상태를 체크해 보고, 실제 파인 튜닝을 위한 두 번째 준비 단계인 데이터셋에 대해 이야기해 보도록 하겠습니다.
혹시, Ollama로 설치한 Model을 WebUI를 통해 대화하는 방법에 대해 궁금하신 분은 이전 작성되었던 아래 글을 참고하세요.
- 한국어 LLM 모델과 토크나이저 교체에 따른 영향 – 나만의 모델 만들기 #5
- Custom model 생성 및 safetensors 저장 방법 – 나만의 모델 만들기 #4
- SentencePiece 토크나이저 정의와 HF 래핑 – 나만의 모델 만들기 #3
- Gemini CLI로 텍스트를 JSON으로 변환하기 – 코드 없이 구현하기 #1
- ComfyUI 간단한 사용 방법 – 워크플로우 구성, 이미지 생성 가이드 #1
llama fine tuning 방법 시리즈
- llama fine tuning 방법 #2 – 목표 설정과 Dataset
- llama fine tuning 방법 #3 – 저사양 PC도 가능한 파인 튜닝
- llama 3.2 1b 파인튜닝으로 한국어 능력 향상시키기 #4