오늘은 OpenAI API 요금에 대해 좀 이야기해 볼까 해요. 대부분의 LLM 기반 API들이 Token(토큰) 단위로 요금을 매기고 있는데, 이 Token(토큰)이라는 개념이 우리 같은 일반인에겐 좀 낯설잖아요. 그래서 OpenAI API 비용이 대충 어느 정도일지 감을 잡기가 쉽지 않죠. 오늘은 이 Token(토큰)이라는 게 뭔지, 그에 따라 OpenAI API의 비용이 어떻게 계산되는지 정리해 보도록 하겠습니다.
OpenAI API 요금은 어떻게 계산될까?
자, 우선 여러 어려운 말을 하기 전에 OpenAI에서 공지하고 있는 비용에 대해 알아볼게요.
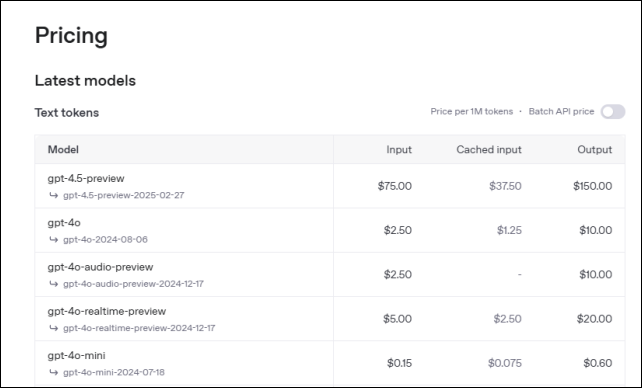
OpenAI API 요금 페이지에서 보면 위 그림과 같이 자세하게 나와있어요. 텍스트를 사용하는 경우의 예로, 1M tokens 사용당 gpt-4o 모델의 경우 input은 2.5달러, output은 10달러, 캐시(Cached input)는 1.25달러가 소요된다고 나와있어요. 일단, 토큰이 뭔지는 잘 모르겠지만, 직관적으로 보이는 것은 ‘입력보다 출력 비용이 크다.’와 ‘입력(지시 또는 질문)의 길이와 출력(gpt의 응답)의 길이에 따라 비용이 정해지는구나!’ 정도는 알 수 있죠.
OpenAI API 요금의 단위, 토큰이란
토큰은 간단히 말해 AI가 텍스트를 처리하고 이해하는 데 사용하는 가장 작은 단위입니다. 우리가 일상에서 단어나 문장으로 생각하고 소통한다면, AI는 텍스트를 토큰이라는 조각으로 쪼개서 분석하고 답변을 만듭니다. 토큰이 단순히 단어 하나와 1:1로 대응하지 않습니다.
토큰이 어떻게 작동하는지 이해하려면 실제 예시를 보는 게 가장 좋습니다. 영어와 한국어를 예로 들어 보겠습니다.
먼저 영어 문장 “I like to run”을 살펴보죠. 이 문장은 띄어쓰기로 보면 “I”, “like”, “to”, “run” 이렇게 네 단어로 나뉩니다. 하지만 OpenAI의 텍스트를 토큰으로 쪼개는 도구는 이 문장을 더 세밀하게 나눠서 약 4~6개의 토큰으로 처리합니다. 왜냐? 단어뿐만 아니라 공백이나 ‘to’ 같은 작은 연결 단어도 토큰으로 계산될 수도 있기 때문이에요.
예를 들어, 토크나이저가 ‘I like to run’을 쪼개면 대략 이렇게 나뉠 수 있습니다”
“I” (1토큰) / 공백 (1토큰) / “like” (1토큰) / 공백 (1토큰) / “to” (1토큰) / “run” (1토큰)
실제로는 토크나이저가 단어와 공백을 상황에 따라 합치거나 나눌 수 있어서 정확히 4토큰일 수도 있고, 6토큰일 수도 있습니다. 중요한 건 우리가 눈으로 보는 “단어 수”와 AI가 보는 “토큰 수”가 다를 수 있다는 점이죠.
그럼 이제 한국어를 예로 들어볼게요. “나는 달리기를 좋아해”라는 문장은 띄어쓰기로 보면 “나는”, “달리기를”, “좋아해” 이렇게 세 단어로 보입니다. 하지만 토크나이저는 이 문장을 훨씬 더 잘게 쪼개서 약 6~8개의 토큰으로 만듭니다. 한국어는 영어와 달리 조사(“는”, “를”)나 동사 어미(“해”)가 의미를 가진 작은 조각으로 따로 인식되기 때문이죠. 아마도, 이렇게 나눠질 수 있습니다.
“나” (1토큰) / “는” (1토큰) / 공백 (1토큰) / “달리기” (1토큰) / “를” (1토큰) / 공백 (1토큰) / “좋아” (1토큰) / “해” (1토큰)
여기서 “달리기”나 “좋아”와 같은 단어는 토크나이저에 따라 더 세부적으로 나뉠 수도 있어서 토큰 수가 6개에서 8개까지도 가능합니다. 영어와 비교하면 한국어가 더 많은 토큰으로 쪼개지는 경향이 있다는 걸 알 수 있어요. 이는 한국어 문법이 단어 하나에 여러 의미 조각을 붙이는 구조 때문이라고 하는데요, 개인적으로는 LLM이나 자연어 처리의 원천 기술이 한국어에서 시작되지 않았기 때문일 거라 생각합니다.
암튼, 토큰은 단순히 단어 수를 세는 게 아니라 텍스트를 AI가 이해할 수 있는 작은 덩어리로 나누는 과정이라는 것. 영어든 한국어든, 우리가 평소에 “단어”라고 생각하는 것보다 더 촘촘하게 쪼개질 수 있다는 것. 이 두 가지를 염두에 둬야 합니다.
실제로 OpenAI API를 사용할 때 토큰 수를 “정확하게” 계산하는 방법은 필요하겠죠? OpenAI에서 제공하는 전용 라이브러리인 tiktoken을 사용하면 GPT 모델에 따라 정확한 토큰 수를 계산해 볼 수 있어요.
간단한, 예제 코드를 볼게요. 앞에서 예시로 봤던 두 개의 문장 “I like to run”, “나는 달리기를 좋아해”의 실제 토큰 수를 계산해 볼게요
import tiktoken
encoder = tiktoken.encoding_for_model("gpt-4o")
textlist = ["I like to run",
"나는 달리기를 좋아해"]
for text in textlist:
tokens = encoder.encode(text)
print(f"'{text}' : 토큰 수는 {len(tokens)}")tiktoken 라이브러리를 임포트 하고요, 사용할 모델로 제가 자주 사용하는 gpt-4o 모델을 지정하여 위와 같이 간단한 코드를 구성합니다. 이제 실행해서 앞에서 예상한 토큰 수가 정확한지 확인해 볼게요.
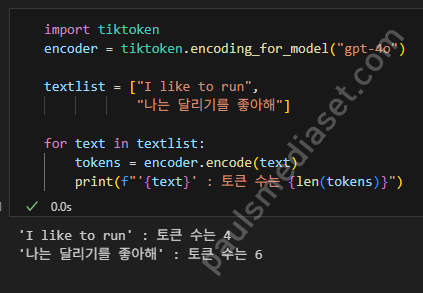
실제 OpenAI API 요금의 단위인, 토큰을 계산하는 라이브러리를 사용해 보니 두 문장 각각 4, 6개의 토큰이 계산되었습니다. 기회가 되면 추후 이 tiktoken 라이브러스의 코드로 분석해 보면 더 자세한 내용을 정리해 볼 수 있겠죠.
그런데, 실제로 OpenAI API를 사용하려면 위와 같은 사용자 문장만 input으로 계산되는 것은 아니에요. 실제로 API 기반의 메시지 코드를 구성해 볼게요.
response = openai.chat.completions.create(
model="gpt-4o",
messages=[{"role": "system", "content": "대답은 친절하고 정중하게 대답해줘."},
{"role": "user", "content": "나는 달리기를 좋아해, 너는?"}]
)위 코드는 실제 OpenAI API를 사용하여 input 메시지를 구성한 거예요. 이 메시지 구성을 보자마자, system의 content와 user의 content 부분이 모두 input 토큰으로 카운트될 것이라는 게 보입니다. 실제로 user 부분이 사용자의 요청 사항에 해당하므로 system 부분은 제외할 수 있지 않을까 생각할 수도 있어요. 뭐, 그럴 수도 있지만, 보다 더 정확한 응답을 얻기 위한다면 필수적인 부분이기도 합니다.
여기까지 보면 ‘프롬프트 구성이 API 사용 비용과 관련해서도 중요하구나.’라는 생각이 들지 않으세요? 다음 시간에는 OpenAI API 요금을 줄이기 위한 방법으로 프롬프트 구성 방법 등에 대해 정리해 보도록 하겠습니다.
- 한국어 LLM 모델과 토크나이저 교체에 따른 영향 – 나만의 모델 만들기 #5
- Custom model 생성 및 safetensors 저장 방법 – 나만의 모델 만들기 #4
- SentencePiece 토크나이저 정의와 HF 래핑 – 나만의 모델 만들기 #3
- Gemini CLI로 텍스트를 JSON으로 변환하기 – 코드 없이 구현하기 #1
- ComfyUI 간단한 사용 방법 – 워크플로우 구성, 이미지 생성 가이드 #1