Qwen3-0.6B fine-tuning 단계별 실습 #2-1 한국어 글쓰기 모델 만들기
오늘은 파인튜닝(fine-tuning)을 다시한번 실행해 보도록 하겠습니다. 지난 번에는 Llama3.2 1b 모델을 기준으로 저사양 PC에서 8일이나 걸려서 진행해 봤죠. 물론, 그 때의 결과는 사실 그다지 좋지 못했어요. 로컬PC 사양으로 다시 실행할 …

오늘은 파인튜닝(fine-tuning)을 다시한번 실행해 보도록 하겠습니다. 지난 번에는 Llama3.2 1b 모델을 기준으로 저사양 PC에서 8일이나 걸려서 진행해 봤죠. 물론, 그 때의 결과는 사실 그다지 좋지 못했어요. 로컬PC 사양으로 다시 실행할 …
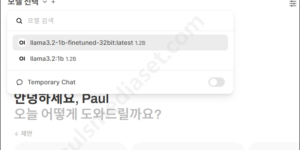
드디어 파인튜닝(Fine-Tuning)이 완료되었습니다. 훈련 시작 시 80시간을 예상했으나, 워낙 오래된 PC라 보니 대략 20시간 정도 더 지연된 것 같습니다. 4일내 끝날 줄 알았지만 5일이 걸렸죠. 오늘은 이전 글 “llama fine …

지금까지 라마 파인 튜닝을 위한 모델을 찾았고, 이 모델이 정상 작동하는지 확인하기 위한 방법으로 Ollama 플랫폼으로 생성하여 Docker를 통해 질문과 답변을 받아 보는 방식 등을 확인해 봤습니다. 또, 파인 튜닝에 …
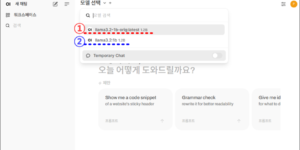
지난 글에서 llama fine tuning을 위한 첫 번째 준비 작업으로 hugging face에서 다운로드한 llama 3.2 1b 모델을 포멧 변경하여 ollama 플랫폼에 맞게 생성하는 것까지 진행해 봤습니다. 오늘은 두 번째 준비 …

오늘부터는 연속하여 llama fine tuning(라마 모델 파인 튜닝)에 대해 이야기해 보려 합니다. 특히 llama fine tuning을 위한 사전 작업과 튜닝 과정을 자세하게 다뤄볼 예정입니다. 지금까지 llama 3.1, llama 3.2를 설치하고 …