Corpus(말뭉치) 준비와 데이터 전처리 – 한국어 AI 모델 만들기 #2
오늘은 나만의 한국어 AI 모델 만들기 두 번째 이야기로, 한국어 학습을 위한 가장 기본적인 Corpus(말뭉치)에 대해 정리하겠습니다. 최근 인공지능(AI)이 사람처럼 글을 쓰고, 질문에 답하고, 번역까지 하는 모습을 자주 보게 됩니다. …

오늘은 나만의 한국어 AI 모델 만들기 두 번째 이야기로, 한국어 학습을 위한 가장 기본적인 Corpus(말뭉치)에 대해 정리하겠습니다. 최근 인공지능(AI)이 사람처럼 글을 쓰고, 질문에 답하고, 번역까지 하는 모습을 자주 보게 됩니다. …

그동안 대형 언어 모델, Tokenizer는 물론, AI (인공지능) 기술과 관련하여 다양한 이야기를 해 왔습니다. 이제부터는 지금까지 다뤄본 기술들을 기반으로 실제 나만의 생성형 AI 모델을 만들어 보고자 합니다. 개인 프로젝트다 보니 …

오늘부터는 지식 증류(Knowledge Distillation)에 대해서 다뤄보도록 하겠습니다. 지금까지 파인튜닝(Fine-tuning)이나 강화학습(Reinforcement Learning)에 대해 몇 번 다뤄봤지만, 지식 증류에 대해서는 처음 다뤄보게 되겠습니다. 지식 증류(Knowledge Distillation) 최근 대규모 인공지능 모델(Large Language Models, …

최근 기술 트렌드 관련 소식을 보다 보면 온디바이스(On-Device)라는 말을 자주 접하게 됩니다. 언 듯 생각하면, 서버와 클라이언트 관계에서 ‘다시 클라이언트 중심의 생태계로 가는 걸까?’라는 생각을 하게 됩니다. 그런 의미로 오늘은 …
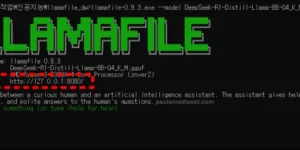
LLM 모델을 실행하는 모듈이라면 Ollama 플랫폼이 유명하죠. 물론, 우리도 여러 차례 다양한 주제로 Ollama를 사용해 보기도 했고요. 최근 들어 LLM 모델을 더 효율적으로 배포하고 활용할 수 있도록 하는 다양한 도구들이 …